$200/hour small project
A typical project that would take a week up to a month.
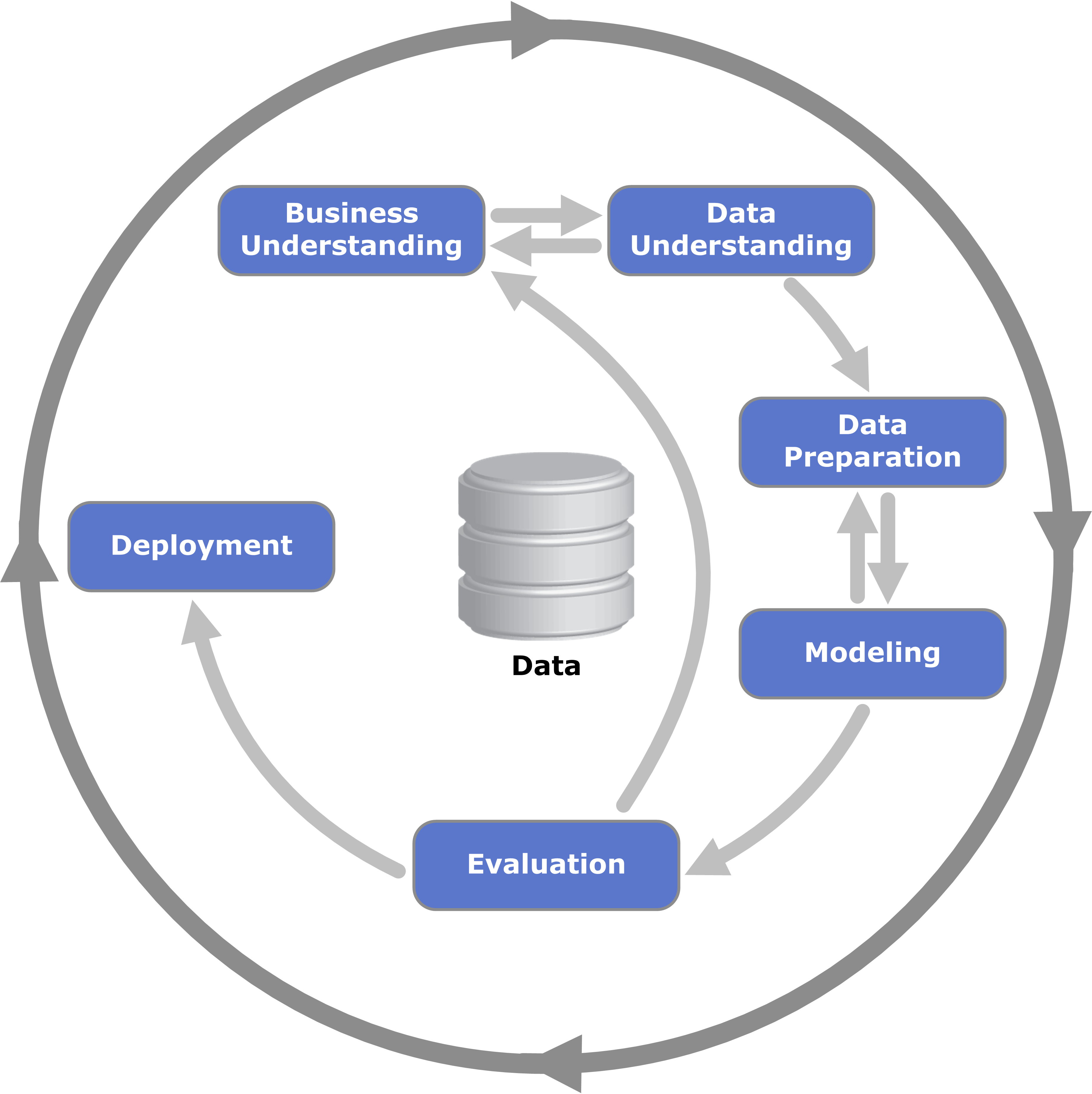
Scenario
Imagine you work for a small retail company that is experiencing a decline in sales. The company wants to understand why this is happening and how to improve its performance. You have been tasked with conducting a data analysis project to investigate the issue.
To begin, you start the project by collecting relevant data on the company's sales, such as transactional data, customer demographics, and product information. You decide to use a CSV file format for this project as the data is relatively small, and CSV is easy to read and write using R and SQL.
After collecting the data, you use ETL processes to extract, transform, and load the data into a local SQL database using R scripts. Then you perform data cleaning, removing missing values, outliers, and inconsistencies in the data.
Next, you conduct exploratory, descriptive, and inferential analysis on the cleaned data using R and SQL. To communicate the insights effectively, you generate interactive and meaningful visualizations using R packages such as ggplot2 and plotly.
Finally, you create a script that automatically ingests newly acquired data into the local SQL database without manual intervention. You also document all R scripts and analysis steps using RMarkdown, including code snippets, visualizations, and narrative explanations.
In conclusion, you successfully completed the project within the timeline, and your analysis provides valuable insights into the company's sales decline, allowing the company to take action to improve its performance.
The following roles are involved in the delivery:
- Data Scientist
- Data Analyst
- Business Analyst
Small Project
-
Data collection: Collection of relevant data in a structured format (e.g. CSV, SQL database) for analysis.
-
ETL process: Automated extraction, transformation, and data loading into a local SQL database using R scripts.
-
Data cleaning: Removal of missing values, outliers, and inconsistencies in the data using R.
-
Data analysis: Conduct descriptive, exploratory, and inferential research on the cleaned data using R and SQL.
-
Visualization: Generating interactive and meaningful visualizations using R packages (e.g. ggplot2, plotly) to communicate insights.
-
Automated Ingestion: Script to automatically ingest newly acquired data into the local SQL database without manual intervention.
-
Documentation: Documentation of all R scripts and analysis steps using RMarkdown, including code snippets, visualizations, and narrative explanations.
-
Timeliness: The project should is completed within one month, with the option to extend the timeline if necessary.
Data Collection
Data Collection: The project's first step is to collect the relevant data. This data should be in a structured format, such as a CSV file or a SQL database, to ensure it is easily accessible and processed efficiently.
- Data Collection: The project's first step is to collect relevant data for analysis. This data can come in different file formats such as CSV, JSON, Parquet, or plain text. Each file format has advantages and disadvantages, and the choice of file format will depend on the project's specific requirements.
a. CSV (Comma-Separated Values) is a simple and widely used file format for data storage. It is easy to read and write using software tools such as R and SQL and is compatible with various data analysis tools. The main disadvantage of CSV is that it can become large and unwieldy when storing large datasets.
b. JSON (JavaScript Object Notation) is a popular file format for data storage, particularly for data transferred between different systems. It is lightweight, human-readable, and supports complex data structures. JSON can be read and written in R and SQL and is compatible with various data analysis tools.
c. Parquet is a columnar file format optimized for storing large datasets compactly and efficiently. It is commonly used in big data environments, providing fast read and write performance. Parquet is supported in R and SQL and is compatible with a wide range of data analysis tools.
d. Plain text is a simple file format storing data as a series of plain text strings. It is easy to read and write in R and SQL and is compatible with various data analysis tools. However, it could be better suited for storing large or complex datasets, as it can become challenging to manage and maintain.
In conclusion, the choice of data file format will depend on the project's specific requirements, such as the dataset's size, the data structures' complexity, and the desired read-and-write performance.
ETL Process
-
ETL Process: Once the data has been collected, the next step is to conduct the ETL (extract, transform, load) process. This process involves extracting the data from its source, transforming it into the desired format, and loading it into a local SQL database. R scripts will be used to automate this process.
-
ETL vs ELT: In the second step of the project, the data will be processed using either an ETL (extract, transform, load) or ELT (extract, load, transform) process. The difference between the two processes is how the data is transformed and loaded into the database.
a. ETL: In an ETL process, the data is extracted from its source, then transformed into the desired format, and finally loaded into a database. This process is commonly used when the database needs more power to handle the data transformation process. The transformed data is stored in a separate database, allowing for the database to be optimized for querying and analysis.
b. ELT: In an ELT process, the data is extracted from its source, loaded into a database, and then transformed into the desired format. This process is commonly used when the database is powerful enough to transform data. The advantage of ELT is that it can reduce the time required for data transformation, as it is performed in parallel with the load process.
The choice between ETL and ELT will depend on the project's specific requirements, such as the size and complexity of the dataset, the desired performance and scalability, and the available resources and technology.
An ETL process will be used for this project, including a time stamp and unique identifier. The timestamp will provide information on when the data was collected, while the unique identifier will ensure that each record in the database has a unique identifier, making it easier to manage and query the data. This step of the ETL process will ensure that the data is organized and ready for analysis.
Data Cleaning
Data Cleaning: The data collected may contain missing values, outliers, or inconsistencies that can affect the analysis results. The data will be cleaned using R. This process will involve removing missing values, correcting discrepancies, and treating outliers as necessary.
- Data Cleansing: In the third step of the project, the raw data file will undergo a data cleansing process to get it into the desired shape for analysis. This process involves removing or correcting any errors, inconsistencies, or missing values in the data.
Data cleansing is a crucial step in data analysis, ensuring the data is accurate, reliable, and consistent. This step can involve several tasks, such as removing duplicate records, handling missing values, correcting inconsistent data formats, and transforming the data into the desired form.
There are two main formats for storing data for analytics: long format and wide format.
a. Long format: In a long-form, each row of the data represents a single observation, describing each observation by several variables. This format is commonly used in time series data, as it allows for the easy analysis of changes in the variables over time. The long form is also easier to read and visualize, as it presents the data in a simple and intuitive format.
b. Wide format: In a wide form, each row of the data represents multiple observations, each described by a single variable. This format is commonly used for cross-sectional data, as it allows for the easy analysis of the relationship between variables. However, the wide form can become difficult to read and visualize when dealing with large and complex datasets.
In conclusion, the choice of format will depend on the project's specific requirements, such as the type and size of the dataset, the desired level of readability, and the particular goals of the analysis. For this project, a long format will be used for its ease of readability and visualization. The data cleansing process will involve transforming the raw data file into a long-form, ensuring the data is organized and ready for analysis.
Data Analysis
Data Analysis: After the data has been cleaned, it is ready for analysis. The analysis will involve descriptive, exploratory, and inferential analysis using R and SQL. Descriptive analysis will summarise the data's characteristics, such as the mean and standard deviation. Exploratory analysis will involve generating visualizations and conducting hypothesis testing to identify patterns and relationships in the data. The inferential analysis will be used to make predictions and generalize findings to a larger population.
- Data Analysis: In the fourth step of the project, the data will be analyzed to answer specific business questions and derive insights. There are several types of data analysis that can be performed, including descriptive analytics, diagnostic analytics, predictive analytics, and prescriptive analytics.
a. Descriptive Analytics: Descriptive analytics is the process of summarizing and describing the characteristics of a dataset. This type of analysis is used to describe the key features of the data, such as the mean, median, and mode, and to produce visualizations, such as histograms and scatter plots, to help understand the distribution of the data.
b. Diagnostic Analytics: Diagnostic analytics explores the data to understand the causes of specific outcomes or patterns. This analysis involves drilling into the data to uncover the root causes of particular events or trends.
c. Predictive Analytics: Predictive analytics uses historical data and statistical models to predict future events or outcomes. This analysis involves building models that use variables to predict future results, such as sales or customer behaviour.
d. Prescriptive Analytics: Prescriptive analytics uses optimization algorithms and simulation models to determine the best course of action. This analysis involves finding the optimal solution to a specific problem, such as scheduling resources or optimizing a supply chain.
Setting alarms and key performance indicators (KPIs) are essential data analysis components. Alarms trigger alerts when specific conditions are met, such as when a data point exceeds a threshold value. KPIs are used to measure the performance of particular aspects of a business, such as sales or customer satisfaction, and to track progress over time.
In conclusion, data analysis is an integral part of the project, as it allows for extracting valuable insights and discovering trends and patterns in the data. The specific type of data analysis performed will depend on the project's particular requirements and the analysis's business goals.
Visualization
Visualization: To communicate insights and results effectively, interactive and meaningful visualizations will be generated using R packages such as ggplot2 and plotly. These visualizations will clearly and concisely represent the findings and help convey the results to stakeholders.
- Visualization: In the fifth step of the project, the data analysis results will be presented clearly and intuitively. Visualization helps to communicate the insights derived from the data and makes it easier for stakeholders to understand and act on the results.
There are several graphical primitives used in data visualization, including points, lines, bars, and shapes. These primitives are combined to create a wide range of charts, including univariate and multivariate charts.
Univariate charts are used to represent data with a single variable, such as a histogram or a bar chart. Multivariate charts are used to describe data with two or more variables, such as a scatter plot or a heat map.
The design of visualization is critical for its effectiveness. The laws of UX play an essential role in determining the best way to present data. Some of the most important rules include the Aesthetic-Usability Effect, Doherty Threshold, Fitts's Law, Goal-Gradient Effect, Hick's Law, Jakob's Law, Law of Common Region, Law of Proximity, Law of Prägnanz, Law of Uniform Connectedness, and Miller's Law.
Laws of UX govern the design of user interfaces and aim to improve their usability and overall user experience. Here are some of the essential laws of UX:
-
Aesthetic-Usability Effect: The Aesthetic-Usability Effect states that users perceive aesthetically pleasing designs as more valuable than less aesthetically pleasing designs. A well-designed interface with an attractive appearance can lead to a more positive user experience.
-
Doherty Threshold: The Doherty Threshold is the amount of time it takes a user to become frustrated with an application. This threshold is influenced by factors such as the task's complexity, the interface's responsiveness, and the overall user experience.
-
Fitts's Law: Fitts's Law states that the time required to move to a target quickly is a function of the target size and the distance to the target. This law is commonly used in the design of graphical user interfaces to determine the optimal size and placement of buttons and other interactive elements.
-
Goal-Gradient Effect states that users are more motivated to complete a task when they are closer to their goal. This effect can be leveraged in the design of user interfaces to increase motivation and engagement.
-
Hick's Law: Hick's Law states that the time it takes for a user to decide is directly proportional to the number of options available. This law is commonly used in designing user interfaces to determine the optimal number of options to present to a user.
-
Jakob's Law: Jakob's Law states that users prefer to use familiar designs and interfaces. This means that designers should strive to make their interfaces friendly and consistent with other interfaces that users are already familiar.
-
Law of Common Region: The Law of Common Region states that objects within a common region are perceived as being grouped. This law can be used in designing user interfaces to group related information and make it easier to understand.
-
Law of Proximity: The Law of Proximity states that objects closer together are perceived as being more related than objects further apart. This law can be used in designing user interfaces to group related information and make it easier to understand.
-
Law of Prägnanz: The Law of Prägnanz states that people tend to perceive complex systems as organized and straightforward. This law can be used in designing user interfaces to simplify complex information and make it easier to understand.
-
Law of Uniform Connectedness: The Law of Uniform Connectedness states that objects connected by a uniform line or contour are perceived as being related. This law can be used in the design of user interfaces to group related information and make it easier to understand.
-
Miller's Law: Miller's Law states that people can only remember about seven pieces of information at a time. This law can be used in designing user interfaces to limit the information presented to a user at any given time.
The laws of UX are an essential part of the design of user interfaces and play a crucial role in determining the overall user experience. By following these principles, designers can create interfaces that are easy to use, intuitive, and aesthetically pleasing.
In conclusion, visualization is a critical step in the analytics project. Effective visualization helps to communicate the insights derived from the data, making it easier for stakeholders to understand and act on the results. The design of the visualization should be guided by the laws of UX to ensure that it is aesthetically pleasing and intuitive for the user.
Automated Ingestion
Automated Ingestion: The final step is to automate the Ingestion of newly acquired data into the local SQL database. An R script will be written to automatically extract and load the new data, eliminating the need for manual intervention.
Automated Ingestion automatically imports and transforms data into a desired format for analysis.
Here are the six steps involved in the automated ingestion process:
-
Data Collection: The first step is to collect the raw data. This can be done through various methods, including manual file transfer, web scraping, or an API.
-
Data Cleaning: Once the data has been collected, it needs to be cleaned to remove any errors, inconsistencies, or irrelevant information. This step is crucial in ensuring that the data is accurate and ready for analysis.
-
Data Transformation: After the data has been cleaned, it needs to be transformed into the desired format for analysis. This may involve merging multiple data sources, aggregating data, or converting data from one format to another.
-
Data Loading: Once the data has been transformed, it needs to be loaded into a data storage system. This can be a database, data warehouse, or data lake.
-
Automation: The final step is to automate the entire process to run overnight or on a regular schedule. This can be done using tools such as chron jobs or scheduled tasks.
-
Output: The final product of the automated ingestion process is a project directory that contains the raw data, the processed data, and any documentation or scripts used in the process. The processed data is saved in an output folder, ready for analysis.
Overnight chron jobs are automated tasks that run during off-hours, typically overnight. These jobs can be used to automate the ingestion process so that the data is ready for analysis when the workday begins. This allows for the efficient use of resources and ensures that the data is up-to-date and accurate.
In conclusion, automated Ingestion is an essential step in any data analytics project. Automating the process allows data to be quickly and efficiently transformed into the desired format, ready for analysis. The final product is a project directory containing all the necessary information, making it easy for data analysts to access and use for their analysis.
Documentation
Documentation: The project must be easily replicable and understandable, all R scripts and analysis steps will be documented using RMarkdown. This will include code snippets, visualizations, and a narrative explanation of the analysis process.
Documentation is an essential part of any data analytics project. It records the steps taken to collect, clean, transform, and analyze data. In addition, it helps others understand the analysis and makes it easier to replicate the work in the future.
RMarkdown or Quatro documents are a great way to document a data analytics project. They allow you to combine text, code, and data in the same document, making it easier to understand the analysis and follow the steps.
Bookdown is a tool that can be used to bundle RMarkdown or Quatro documents into a single, organized document. This document, called a "book", can include a table of contents, sections for each step in the analysis, and figures and tables to illustrate the results.
By using RMarkdown, Quatro documents, and bookdown to document the data analytics project, you can ensure that the steps and results are well-documented and easily accessible to others. This makes it easier for others to understand the analysis and replicates the work in the future.
In conclusion, documentation is an integral part of any data analytics project. By using RMarkdown, Quatro documents, and bookdown, you can ensure that the steps and results are well-documented and easily accessible to others. This makes the analysis more transparent and reproducible.
Timeliness
Timeliness: The project timeline is one month, with the option to extend it if necessary. The project should be completed within this timeframe to ensure it is delivered within budget and meets the stakeholders' requirements.
Timeliness is essential to any data analytics project, as it often needs to meet specific deadlines or time frames. Two main project management approaches can be used for data analytics projects: Agile sprints and the Waterfall approach.
Agile sprints are a popular approach for data analytics projects. They are usually two-week sprints where a team works together to complete specific tasks. This approach is ideal for rapidly changing projects or needs to be flexible in response to new information. The Agile sprint approach allows the team to work quickly and iteratively and adjust the project as required.
The Waterfall approach, on the other hand, is a linear, sequential approach to project management. This approach is more suitable for projects with a well-defined scope, timeline, and budget. This approach completes each project phase before moving on to the next stage. This approach is ideal for projects with a clear end goal and must follow a specific set of steps to reach it.
In addition to choosing the right project management approach, it is vital to use a project schedule and catalogue. The project schedule should include the following:
-
A timeline of the tasks to be completed.
-
The start and end dates for each job.
-
The dependencies between tasks.
The project catalogue should include detailed information, including its goals, objectives, and expected outcomes.
Finally, it is crucial to estimate the total cost of the project. This includes the cost of resources, such as software and hardware, and the cost of human resources, such as salaries and benefits. The total cost estimate should be based on the project's scope, the resources required, and the timeline for completion.
In conclusion, timeliness is a crucial aspect of any data analytics project. Choosing the right project management approach, using a project schedule and catalogue, and estimating the project's total cost can ensure that the project is completed on time and within budget.
Ready to take your data analysis to the next level? Book your time with us today and let our team of experts help you unlock the full potential of your data. With our step-by-step process, we'll work with you to ensure your project is completed on time, within budget, and with maximum impact. Don't wait; book your time now and get started on your data journey!